
This article briefly describes our experience of solving a partial case of text recognition problem. It skips implementation details and some algorithm steps are simplified for better understanding.
Problem statement
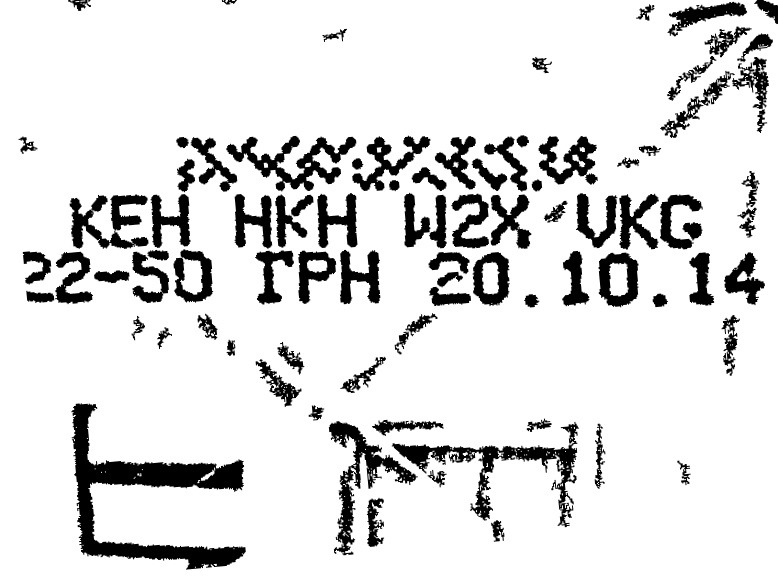
As an input we have a photo of a cigarette pack. It contains special formatted code (four triples of characters separated by whitespaces), which is usually printed on the bottom of a pack.
This code must be recognized and returned as a string.

Input image examples
Code recognition approach
Looking for a solution first we tried to use standard OCR modules (such as Tesseract). But it turned out that the achievable quality of recognition for our partial case is not sufficient because of various reasons. For example images can be blurred or rotated. Besides, standard approaches don’t use additional information, such as code format or the fact that codes are printed with a special font, which is the same for all packs. At last we came up with our own algorithm.
In our approach we divide a solution into three main parts.
- The first one is finding the code
- The second part is separating its characters
- And finally the recognizing each of characters
Code detection
It may look as a complex task however. This part consists of 4 steps:
- Image preprocessing.
- Noise filtering and extracting bounding rectangles.
- Detecting rotation angle and possible code locations.
- Selecting code area.
Image preprocessing
During this step we convert an input photo to binary image. With the help of OpenCV library we perform 3 following algorithms:
- Converting image to grayscale format (cvtColor).
- Normalization (normalize).
- Performing Gaussian adaptive threshold (adaptiveThreshold).

a. Initial image

b. Grayscale

c. Normalized

d. After performing Gaussian adaptive threshold (binary image)
Noise filtering and extracting of bounding rectangles
On this step we find connected areas of black pixels using Breadth-First Search algorithm. The area that contains too few points should be considered as noise and be removed from the image. For the rest of them we extract bounding rectangles. Rectangles that don’t look like a shape of a character aren’t taken into consideration.
This video shows how our algorithm works on a particular example. Red areas are considered to be noise. Yellow rectangles are ignored because of inappropriate shape. Green rectangles will be used further.

a. Image before filtering

b. Filtered image with extracted rectangles
Detecting rotation angle and possible code locations
In this part of the algorithm we find groups of rectangles located at the same line or deviate insignificantly from it (for each image there will be several of them). With the help of these lines we calculate photo rotation (as average angle of all lines). Then we extract smaller areas, each containing a line and correspondent rectangles.

a. Group of rectangles with correspondent lines
b. Image after rotation


c. Extracted areas
Selecting code area
From the previous step we’ve received several areas, one of which contains code we are looking for. Now we consider each text area image as a matrix, where all black pixels are 1s and all white pixels are 0s. For each column we calculate total amount of 1s and denote it as array сolumn_sum. Notice, that the columns, which belong to areas with whitespaces, have lower value than columns, which are the parts of characters.
Using this and the fact that we can calculate an approximate width of the characters triple (it’s possible because height and width ratio of every character printed with code’s font are always the same) we can determine code text area using next algorithm:
- For each element in сolumn_sum calculate an average on the interval with a center in this element and length which is equal to approximate width of character triple. Denote it as new array mean_сolumn_sum.
- For each element in array mean_сolumn_sum consider the same intervals as in previous step. Select elements which have maximum values on correspondent intervals. If among such elements we find four located at the same distance that means we’ve found area with the code. Besides, these four elements corresponds to central columns of character triples.



a. Area contains code




b. Area without code
Extracting characters
Since the location of centers and approximate width of triples are already known, we can extract the areas where these triples are depicted. Then each triple should be processed separately. We starting by cutting off needless space around a triple. Then referring to the fact that all characters have the same width we can determine where one letter ends and another starts. In this way characters can be extracted for further recognition.

a. Separation of the characters in the triple.
Code recognition
In the last part algorithm works separately with every single character that we’ve received from the previous part. As a result we will get all of them recognized. Actually recognizing a single character image is a well-known problem which became a classical machine learning task. There are several solutions but we have implemented our own simple algorithm.
It consists of 2 steps:
- Training a machine learning classifier
- Character recognition
Training a machine learning classifier
This step is preprocessing of data that is necessary for recognition. For every character (both letter and number) we create a training set by collecting large amount of images with it depicted. The training process is a creation of “average” image for each of characters.
Training process for “0″ character.
Character recognition
Now, when we have an “average” image for each letter and number all the characters from input code can be recognized with the simple hypnotize function:
- Calculate the “error” between each pattern and input character image:
- Resize input image to the same size as a pattern has.
- For each pixel in input image calculate absolute difference between its value and the value of correspondent pixel in the pattern. The average value of all absolute differences gives us sought-for “distance“.
- Find the pattern with the minimal “error” from input image. The character which is depicted on it is the one we are looking for.
OCR algorithm accuracy
We had nearly 200 images to test our algorithm. We split all images into 3 groups:
- Good images (are expected to be well recognized).
- Acceptable images.
- Bad images (with low quality).

a. Good image example

b. Acceptable image example

c. Bad image example
The algorithm was tested in two different ways. First we checked whether every single character is recognized correctly and then verified the whole code (if at least one character was recognized improperly then the algorithm failed on the code).
You can see the result in the table below.
| Image quality | Whole code recognition rate, % | Single character recognition rate |
|---|---|---|
| Good | 72% | 96% |
| Acceptable | 42% | 88% |
| Bad | 27% | 77% |
OCR algorithm performance
Originally algorithm was designed for portable industrial scanner based on Raspberry Pi and work with camera stream in real time. Since Raspberry Pi has very limited computing resources, the requirements of algorithm performance are very high. The complexity of our algorithm is O(nm), where n is the image width and m is the image height in pixels. It means that every part of the algorithm runs quicker (or at least not slower) than image reading. This is the benefit of our algorithm in comparison with sliding window approach, which also can be used for code detection.
Conclusion
In this article we described our experience in solving a partial case of OCR problems. The algorithm has high accuracy of single character recognition even working with bad quality images.
References
- Optical character recognition (OCR) is the mechanical or electronic conversion of images of typewritten or printed text into machine-encoded text.
- Breadth-First (BFS) search is an algorithm for traversing or searching tree or graph data structures.
- OpenCV (Open Source Computer Vision) is a library of programming functions mainly aimed at real-time computer vision.
Anton Puhach, Mike Makarov





