

For a long time, great sound was all about the physical stuff: the speaker’s materials, the box it came in, and how precisely everything was built. While physics still matters, the biggest breakthroughs in audio are now happening inside computers and software.
Think about photography. It used to be that a good photo needed a big camera lens and sensor. But now, our smartphones take amazing pictures, often better than dedicated cameras. This happened because of “computational photography.” Smart software corrects lens issues, combines multiple shots, and improves images instantly.
Audio is going through a similar change. Today’s speakers, from small portable ones to living room soundbars, use “computational audio” to deliver incredible sound and immersion that would be impossible for their size otherwise. The future of audio isn’t just about making sound, but understanding and adapting it.
This is where Computational Audio (CA) comes in. It blends computer science, artificial intelligence (AI), and digital signal processing (DSP). CA intelligently transforms raw audio data into useful information, which then helps create a better listening experience. Thanks to powerful, affordable computer chips, what was once just a lab idea is now a key feature in everyday electronics.
This post explores the computational audio revolution, detailing its core principles, key applications like AI-powered room calibration and 3D sound from a single speaker, and analyzing its impact on both the market and product development.
- What is Computational Audio? The Smart Way Sound Works
- The Self-Aware Speaker: AI-Powered Acoustic Room Calibration
- How Room Calibration Works: A Three-Step Process
- Engineering Immersion: Big Sound from Small Speakers
- The Competitive Arena: How Industry Leaders are Weaponizing Smart Audio
- Building the Future of Audio: The Engineering Challenge and Your Development Partner
What is Computational Audio? The Smart Way Sound Works
To understand the next wave of audio tech, we need to get familiar with computational audio. Simply put, Computational Audio (CA) is where computer science meets digital audio analysis, processing, and creation. It’s more than just a fancy name for audio engineering; it’s a huge expansion of the field.
CA is truly interdisciplinary, combining areas like machine learning, artificial intelligence (AI), signal processing, and human-computer interaction with traditional audio sciences such as acoustics and sound engineering. Major groups like the IEEE are even setting standards for this growing field, showing how important it is.
The main idea behind computational audio is to intelligently transform raw sound signals into a finely tuned listening experience. It takes audio data, turns it into useful information, and then uses that information to optimize the sound for human ears.
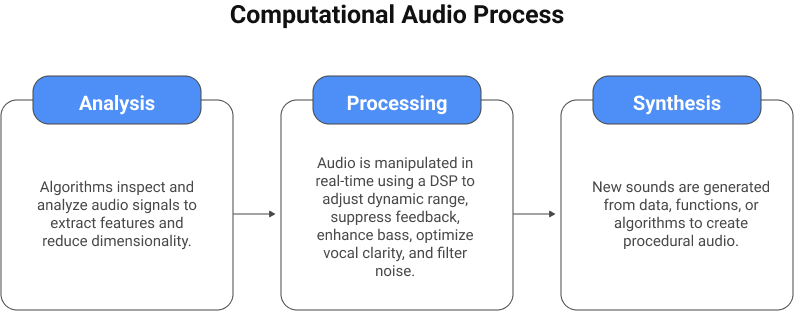
Analysis: Understanding the Sound
This is the “understanding” phase. Algorithms are used to visually and programmatically inspect and analyze audio signals. This can involve sophisticated techniques like feature extraction to identify specific characteristics of the sound (e.g., the timbre of an instrument, the phonemes in speech) and dimensionality reduction to make sense of vast amounts of audio data.
Processing: Making the Magic Happen
Once the audio is understood, it can be manipulated in real-time. This is where the magic happens. A dedicated audio chip, powered by a DSP, can perform a “symphony of adjustments”. These adjustments include dynamic range compression to balance loud and quiet parts, feedback suppression, bass enhancement, vocal clarity optimization, and advanced filtering to remove unwanted noise. This forms the core of audio processing software within the device.
Synthesis: Creating New Sounds
Beyond simply modifying existing audio, CA can also generate entirely new sounds from data, functions, or algorithms. This practice, sometimes referred to as procedural audio, aims to compute the entire gamut of possible sound interactions, for example, within a virtual world, rather than relying on pre-recorded samples.
Why Now? The Tech and Economic Shift
The complex, real-time processing needed for computational audio has been technically possible for years, but it used to be too expensive for everyday products. The good news is, the cost of powerful signal processing chips has dropped dramatically. Now, it’s affordable to put advanced processors, like Apple’s custom S-series silicon, directly into consumer speakers. This built-in intelligence lets devices run complex tuning and algorithms in real-time – something once only found in high-end studios or research labs.
This move from hardware-focused to software-defined audio has big implications. Old speakers were static; their sound was fixed by their physical build. Computational audio breaks this barrier. By treating audio as flexible data, a single piece of hardware can be programmed to produce many different sound profiles. The final sound is no longer just about the physical parts, but a “harmonious union” of design, speaker setup, and the actual sound produced. The software running on the audio chip becomes just as, if not more, important than the hardware itself in shaping what you hear.
What’s more, this software-driven approach turns audio devices from fixed products into dynamic platforms that can be updated. Because their core functions are software-controlled, smart speakers can get better and add new features long after you buy them. Imagine getting virtual DTS:X surround sound or an AI-powered dialogue enhancement mode through a simple software update years later.
This is a huge change from the old “buy it and it’s fixed” model. It transforms the relationship between companies and customers from a single sale to an ongoing service. This opens doors for new business models, like feature subscriptions, and significantly extends the useful life of the hardware. For engineering teams, the challenge isn’t just the initial launch anymore; it’s about building strong, secure software that can handle continuous updates, often with the help of specialized development partners.
The Self-Aware Speaker: AI-Powered Acoustic Room Calibration
Every audiophile, from the casual listener to the dedicated enthusiast, has unknowingly contended with the most influential and unpredictable component of their sound system: the room itself. The physical space in which a speaker is placed dramatically alters the sound it produces. Hard surfaces like windows and bare walls cause sound waves to reflect, while soft furnishings like carpets and curtains absorb them. The dimensions of the room create standing waves, which can cause certain bass frequencies to become overwhelmingly “boomy” while others seem to disappear entirely. The result is that even the most expensive, perfectly engineered speaker can sound muddy, harsh, or unbalanced in an acoustically challenging environment.
The intelligent solution to this universal problem is AI-powered room calibration. This technology uses a form of “spatial awareness” to analyze the unique acoustic properties of a room and then digitally customizes the audio output to compensate for the room’s flaws. The goal is to deliver a neutral, balanced sound profile that is faithful to the original recording, regardless of the speaker’s placement.
How Room Calibration Works: A Three-Step Process
Here’s a look at how smart room calibration adjusts your speaker’s sound:
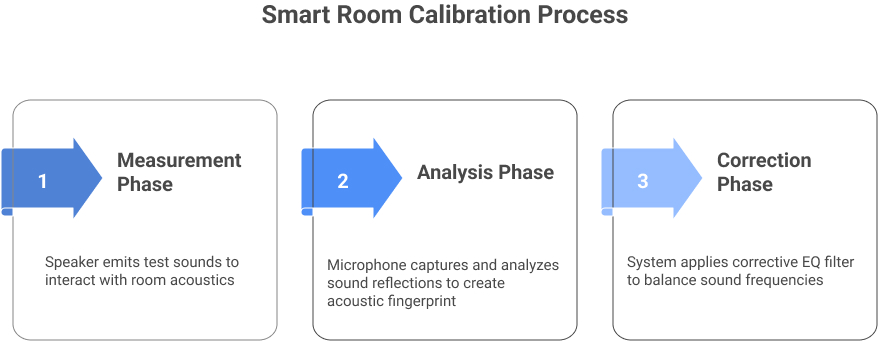
1. Measurement Phase
It starts with your speaker playing a series of test sounds. These can be specific tones or wide frequency sweeps designed to interact with your room’s acoustics.
2. Analysis Phase
A microphone listens to how these test sounds behave in your space. It picks up reflections off walls, ceilings, floors, and furniture. The system’s AI and signal processing algorithms then analyze this data, creating a detailed “acoustic fingerprint” of your room. It does this by comparing the recorded audio to the original test signal. Using a mathematical process called deconvolution, the system calculates the Room Impulse Response (RIR) – a unique digital signature of the room’s acoustics. This RIR is then put through a Fast Fourier Transform (FFT), which shows exactly which frequencies are being over-emphasized (peaks) or suppressed (dips).
3. Correction Phase
Once the system pinpoints the problematic frequencies, it creates a corrective inverse EQ filter. Think of this as a set of digital “knobs” precisely tuned to offset the room’s effects. It turns down frequencies the room boosts and raises those it cuts, ensuring the final sound is balanced, clear, and true to the original recording.
This “compensation curve” is then applied by the speaker’s Digital Signal Processor (DSP). For example, if your room makes 100 Hz frequencies too loud, the filter will reduce the speaker’s output at 100 Hz by the right amount. This correction is applied to all audio played through the speaker in real-time. The result? The room’s influence is effectively neutralized, letting you hear the sound exactly as the artist or director intended.
How Room Calibration Works in Your Devices
This smart audio technology shows up in consumer products in a few main ways, each with its own pros and cons for users:
- User-Guided Approach (e.g., Sonos Trueplay): Sonos led the way with Trueplay, which uses the consistent, high-quality microphone in Apple’s iPhones or iPads. The Sonos app tells you to walk around the room, waving your device, to create a detailed 3D map of the room’s sound. The main downside has been its reliance on Apple devices; Sonos has explained that the wide variation in Android phone microphones made it hard to implement there.
- Automated Approach (e.g., Apple HomePod, Sonos Auto Trueplay, Amazon Echo Studio): This is the next level of convenience, as you don’t need a separate device. Products like the Apple HomePod and portable Sonos speakers (Move, Roam) have built-in microphones. These devices automatically and continuously perform sound calibration. For instance, the HomePod constantly listens to sound reflections to understand its position (like being against a wall or in open space) and adjusts its sound in real-time. Similarly, Sonos’s Auto Trueplay automatically retunes its portable speakers when they move to a new environment, such as from your living room to the patio.
- App-Driven Approach (e.g., LG AI Room Calibration): Other systems, like LG’s, use a dedicated smartphone app for a one-time calibration. You place your phone at your main listening spot and start the calibration via the app. The soundbar then plays test tones, and the app uses your phone’s microphone to analyze the room. For accurate results, you need to ensure the room is quiet and stay in the designated spot during the test.

While powerful, room calibration software isn’t a magic bullet for bad setups; it works best when speakers are already placed well, like symmetrically and away from corners that can cause boomy bass.
This automated calibration is a huge step in democratizing high-fidelity audio. What was once exclusive to professional studios, requiring expensive gear and expertise, is now a push-button feature in consumer speakers, thanks to affordable processors and high-quality microphones. This makes advanced audio accuracy accessible to everyone, turning “audiophile-grade” features into a standard expectation in premium electronics.
This technology also has interesting strategic implications. Sonos Trueplay’s reliance on consistent Apple microphones created a “sticky” experience for Apple users but exposed a challenge for open ecosystems: varied third-party hardware (like Android phones) can limit software features. This pushes companies to either control their hardware stack, like Apple, or integrate necessary sensors directly into their products. Sonos’s addition of built-in microphones to its new Era speakers for Android users is a direct example of how software goals now shape hardware strategy.
Engineering Immersion: Big Sound from Small Speakers
Modern minimalist aesthetics conflict with traditional immersive audio setups that require many speakers and cables. How can a single soundbar or portable speaker create the convincing illusion of sound all around you? The answer lies in sophisticated directional sound and clever manipulation of how we perceive audio.
Part 1: Beamforming – Directing Sound with Precision
Beamforming is key to creating spatial audio from compact sources. This signal processing technique uses multiple speaker drivers to precisely control sound direction. By adjusting the timing and volume of sound to each driver, the system creates stronger sound in desired directions (constructive interference) while canceling it out elsewhere (destructive interference).
This complex process requires powerful Digital Signal Processors (DSPs) to calculate real-time adjustments. The physical arrangement of the speaker array is crucial, determining the shape and steerability of the sound beam.
Manufacturers use beamforming for various listening modes:
- Stereo Widening: Projects sound outward, making the soundstage feel much wider than the speaker itself.
- 3D Immersive Mode: Beams sound at angles to walls and ceilings, creating reflections that trick ears into perceiving sound from all around and above, simulating multi-speaker surround sound.
- Room Fill: Creates an ultra-wide “sweet spot” for multiple listeners, ideal for social settings.
The Apple HomePod is a prime example, with beamforming tweeters that separate and direct sounds. It beams vocals centrally while reflecting ambient sounds off walls for an enveloping experience. Advanced versions even use AI to track and direct enhanced speech beams to moving listeners, a revolutionary step for hearing aids and far-field microphones.
Part 2: Virtual Surround and Spatial Audio – Hacking Human Perception
Beyond physically directing sound, the second part involves tricking the brain into perceiving sound from where it isn’t. This relies on psychoacoustics, the study of how physical sound properties relate to our perception. Our brains use several cues for sound localization:
- Interaural Differences: Minute time (ITD) and loudness (ILD) differences between when sound reaches each ear, due to our head’s separation, help locate sounds.
- Head-Related Transfer Function (HRTF): The unique shape of our head and outer ears subtly filters sound frequencies based on direction. HRTF is a mathematical model of this filtering. Applying a digital HRTF to audio can create the precise directional cues our brain expects, “placing” sounds virtually in 3D space.
These principles power modern immersive audio:
- Virtual Surround Sound: Aims to replicate multi-channel surround sound (like 5.1 or 7.1) using just two speakers (e.g., a soundbar). It uses HRTFs and other processing to create the illusion of rear and side channels.
- Spatial Audio & Dolby Atmos: The next generation. Instead of fixed channels, these formats are object-based. Sound designers place individual sounds (e.g., a bee, a helicopter) as “objects” in a 3D virtual space. Compatible devices use beamforming and HRTF to render these objects in their perceived positions, creating a true 3D “sound bubble” that’s more realistic than channel-based surround.
Developing these technologies requires a deep, interdisciplinary understanding, blending DSP engineers, AI specialists, and perceptual scientists. Rigorous human listening tests are as crucial as objective measurements for success.
This technological shift has also sparked a new “format war” around immersive audio ecosystems. Dolby Atmos, dominant in movies, TV, and now music streaming, creates a strong incentive for consumers to buy compatible hardware. This drives sales of Atmos-enabled devices, encouraging more content creators to adopt the format, shifting the competitive focus from if a device supports Atmos to how well it renders it. Proprietary innovations in hardware and audio software development (like Apple’s real-time room sensing or Sonos’s advanced drivers) become key differentiators, as companies compete to deliver the most compelling spatial audio from standardized formats.
The Competitive Arena: How Industry Leaders are Weaponizing Smart Audio
In the contemporary consumer electronics market, the computational audio technologies detailed above are no longer niche, “nice-to-have” features. They have become central pillars of product design, marketing strategy, and competitive differentiation. The battle for supremacy in the premium audio space has shifted from a simple contest of physical specifications—driver size and wattage—to a more complex war of intelligence, adaptation, and user experience.
An analysis of the flagship products from the industry’s leading brands reveals distinct strategies for leveraging computational audio to capture market share.
Apple (HomePod)
Apple excels through deep vertical integration. By designing its own S7 chip, it unlocks “advanced computational audio” features tightly integrated into its ecosystem. This custom processor powers real-time room sensing and seamless Spatial Audio with Dolby Atmos. Apple’s key edge is not just the tech, but its smooth integration with other Apple devices – like effortlessly transferring audio from an iPhone or creating an intelligent home theater with Apple TV.
Sonos (Arc Ultra)
Sonos builds on its reputation for acoustic excellence and user-focused features. The Arc Ultra is an audio powerhouse with a complex 14-driver design. Beyond advanced Trueplay room calibration, its standout AI feature is a sophisticated “Speech Enhancement” tool. Developed with the RNID, it offers four customizable levels of dialogue clarity, showing a strong focus on accessibility and solving a common pain point for viewers.
Samsung (Q-Series Soundbars)
Samsung’s strategy leverages its dominant TV business. Its flagship soundbars feature “Q-Symphony,” which syncs the soundbar with Samsung TV speakers and their Neural Processing Unit (NPU) for clearer dialogue and a more immersive sound. Samsung heavily promotes AI features like “Active Voice Amplifier Pro,” which separates voices from background noise in real-time, and “Dynamic Bass Control” for clear low frequencies.
JBL (Bar Series)
JBL targets users who prioritize power, immersion, and flexibility, especially for gaming and action movies. The Bar 1300 MK2 boasts high power output and an 11.1.4-channel setup. Its most innovative features are detachable, battery-powered wireless rear speakers for true surround sound and an “AI Sound Boost” processor that optimizes audio distribution for maximum impact without distortion.
Bose (Smart Soundbars)
Bose leverages its strong brand for quality audio and user-friendly design. Its products include the proprietary ADAPTiQ room calibration and a headline feature called “A.I. Dialogue Mode.” This AI analyzes content in real-time to automatically balance voice levels against background sounds and music, ensuring dialogue is always clear without manual adjustments.
Comparative Analysis of Computational Audio Features in Flagship 2025 Audio Devices
To provide a strategic overview for product managers and engineers, the following table distills the key computational audio features and market positioning of these leading competitors. This format allows for rapid identification of industry trends, competitive gaps, and the “table stakes” features required to compete in the premium audio segment.
| Feature Category | Apple HomePod (2nd Gen) | Sonos Arc Ultra | Samsung HW-Q990F | JBL Bar 1300 MK2 | Bose Smart Ultra Soundbar |
| Core Processor/Engine | Apple S7 Chip | Proprietary Class-D Amplifiers & DSP | Proprietary DSP | Proprietary DSP | Proprietary DSP |
| Room Calibration Method | Automated/Continuous via built-in mics (Room Sensing) | User-guided via app (Trueplay) & Automated on-device (Quick Tuning) | Automated via built-in mics (SpaceFit Sound Pro) | Automated via built-in mics (Sound Calibration) | User-guided via headset (ADAPTiQ) |
| Immersive Audio Tech | Beamforming 5-tweeter array, Spatial Audio with Dolby Atmos | 14 drivers incl. upward & side-firing, Sound Motion™, Dolby Atmos | 11.1.4 channels, upward & side-firing drivers, wireless rears, Dolby Atmos | 11.1.4 channels, 6 up-firing drivers, detachable wireless rears, Dolby Atmos | 9 drivers incl. upward-firing, PhaseGuide, Dolby Atmos |
| Key AI-Branded Feature | Advanced Computational Audio for Real-Time Tuning | AI Speech Enhancement (4 levels) | Active Voice Amplifier Pro & Q-Symphony | AI Sound Boost & SmartDetails | A.I. Dialogue Mode |
| Primary Market Differentiator | Deep Ecosystem Integration & Simplicity | Acoustic Purity & User-Centric Accessibility Features | Synergy with Samsung TV Ecosystem | Maximum Power, Immersion & Flexibility (Gaming Focus) | Brand Recognition & Voice Clarity |
This analysis highlights two key market trends. First, the widespread “AI-ification” of product marketing, where “AI” is a powerful buzzword for “smart” features. For engineers, this means mastering a spectrum of AI solutions, from complex machine learning to sophisticated DSP algorithms, to meet client needs and budgets.
Second, the market is undergoing strategic fragmentation. Instead of one-size-fits-all products, companies are optimizing for specific, high-value use cases. Sonos targets dialogue clarity, JBL aims for gamers, and Samsung leverages its TV ecosystem. This specialization creates opportunities for new players to succeed by serving underserved niches with highly tailored computational audio features.
Building the Future of Audio: The Engineering Challenge and Your Development Partner
Creating modern, intelligent audio devices is complex. A competitive product is an ecosystem where embedded firmware, advanced AI, mobile apps, and cloud infrastructure must harmonize, demanding multi-disciplinary engineering beyond traditional design. Navigating this requires a development team with expertise across a wide technology stack, as a single component’s failure impacts the user experience.
This is why a strategic development partner is crucial, especially for companies seeking custom audio solutions or building IoT audio devices. Many traditional electronics firms excel in hardware but often lack the specialized in-house software teams for AI/ML, cloud architecture, and cross-platform mobile development, creating a talent gap filled by specialized firms like Developex.
With over 23 years in the market, a team of over 350 professionals, and deep expertise in Audio & Video and Consumer Electronics, Developex is uniquely positioned to help companies navigate the complexities of the sonic revolution. We offer end-to-end capabilities across the entire modern audio product stack, from low-level embedded firmware to high-level cloud and AI services:
- Embedded Software Development: This is the core foundation—optimized, real-time firmware and middleware for processors and microcontrollers. It manages hardware, runs the operating system, and includes low-level drivers for audio components. This requires deep expertise in C/C++ and Assembly, across various chipsets. Our expertise in embedded audio development ensures a robust base for your product.
- AI/ML & DSP Integration: The “intelligence” layer, involving selecting, training, and optimizing complex algorithms for key features. This ranges from traditional DSP for equalization to advanced neural networks for psychoacoustic modeling and speech enhancement. It requires specialists in signal processing theory and modern machine learning.
- Mobile App Development For Audio Devices: A smooth, intuitive companion app is essential for setup, Wi-Fi configuration, user accounts, streaming service integration, and firmware updates. High-quality apps need skilled native iOS/Android developers or cross-platform experts. Our proven track record in mobile projects makes us an ideal partner for smart speaker development.
- Cloud & Backend Solutions: Many advanced audio features rely on robust cloud infrastructure. Multi-room audio sync, user profiles, voice assistant integration, and over-the-air (OTA) updates all depend on scalable, secure cloud services.
- Third-Party Integrations: Modern speakers must connect seamlessly to a growing ecosystem of external services, including music streaming (Spotify, Apple Music), voice assistants (Alexa, Google Assistant), and smart home standards (HomeKit, Matter). Managing these APIs and ensuring stable integrations is a significant development task, and one that Developex excels at.
- Comprehensive QA & Testing: With so many interconnected layers—hardware, firmware, AI, mobile app, cloud—thorough Quality Assurance is crucial. A dedicated testing team is needed for both automated and manual testing to ensure flawless functionality, performance, and security across the entire ecosystem
Our flexible engagement models, which range from augmenting an existing team with specific experts (outstaffing) to taking on full, project-based development, allow our clients to get the precise engineering support they need, when they need it. If you are ready to develop a next-generation audio solution that stands out in a competitive market, you need more than just coders; you need an experienced engineering partner.
Contact Developex today to discuss how our dedicated teams can help you build the future of sound.





