For one of our projects we needed to receive, store and display to a UI a large amount of data in realtime. This data is generated by devices located around the world and represented network activity, device location and some other information. Performance was a key key metric for the project. End user should be able to track any device in as close to real time as possible, Whether they have 3 devices or 30,000.
The problem was how to receive all input data, process it and display it quickly.
We used a Redis cache on the Azure platform to solve the problem. Before Redis we’ve tried to use Azure Tables as a free, cloud-based and NoSQL database. But the performance of this service was not good enough, and it had some restrictions inappropriate for the project: max record size 1Mb, max field size 64Kb.
Why Redis?
Because it is the fastest in-memory database today. As Redis stores data in RAM technology, access to this data is very fast. Redis supports many different data types. In the context of our project, a hash set is a useful data type because it allows us to store objects and change required properties without affecting the whole object. Redis has the ability to create and use custom data structures. Redis suggests two basic modes for data storage: Pipelining and Multiplexing. While the first method is faster the second warrants the execution of only one set of commands at a time (like transactions) in sequence.
With Redis it is possible to build a cluster. Although it must be acknowledged that this cluster guarantees neither consistency, nor availability the Redis cluster increases reliability and speed.
Of course Redis also has disadvantages. The main ones:
- It is single threaded.
- There is a high possibility that part of the data is lost, especially when we cache a large bulk of data.
The first disadvantage is actually is not a disadvantage since Efficiency is provided by Azure. The second problem we solved by using blob-objects. They are significantly slower but acceptable on small amounts of data managed in blobs.
Why Azure platform?
Actually, there are a lot of platforms compatible with the Redis cache and tools to manage it. We’ve already been using Azure products in the project: Azure Blobs and Azure Search. It made sense to continue to use the platform. Azure gives us handy set of features:
- Replication,
- Useful interface to show and manage Redis database,
- Easy database scaling.
For the future, it is important to have the ability to build a Redis-cluster and Azure also allows us to do it.
Implementation of Redis
On our project we use Redis to cache data from various devices that work around the world. Redis (and blobs) cache data about a device, its network state, geo-data (where devices are located), any counters (like, how many devices in one country, analytics). We use strings, set, and hash set data types.
Screen 1 displays a hash set data structure in Redis. Key is some unique key, like geolocation. Name is unique sub-key, like name of country. Value is any text value, like how many devices are located in the country.
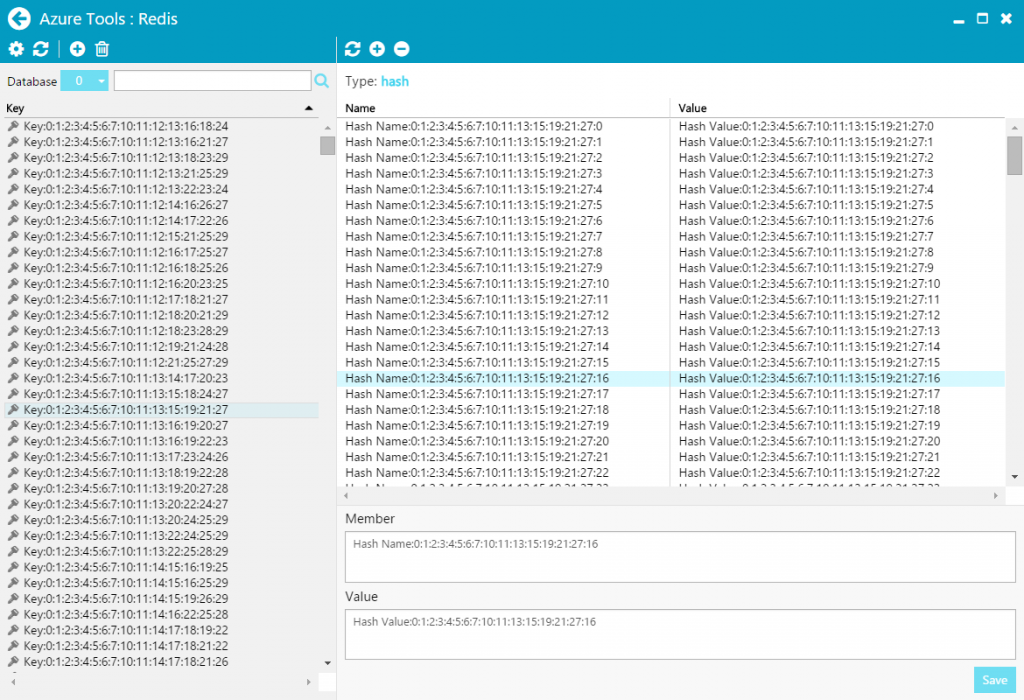
Screen 1. Typical data structure in Redis. The UI from free, cross-platform, open source tool for Microsoft Azure developers
The Screen 2 displays a typical loading of the system. The blue chart represents how many data items were read from Redis cache. The purple chart displays how many data items are read from blobs (that cover Redis). Around 88.3% of data was read from the Redis cache, at a good rate.
Conclusion
Finally, the commercial project we’ve developed is able to manage up to 150 millions devices in real time. Some nonsignificant amount of data is lost but blobs are able to compensate. Tools used were cost effective (see Azure Redis Cache Standard plan) but still allow us to build a well scalable application that works reliably and very fast.
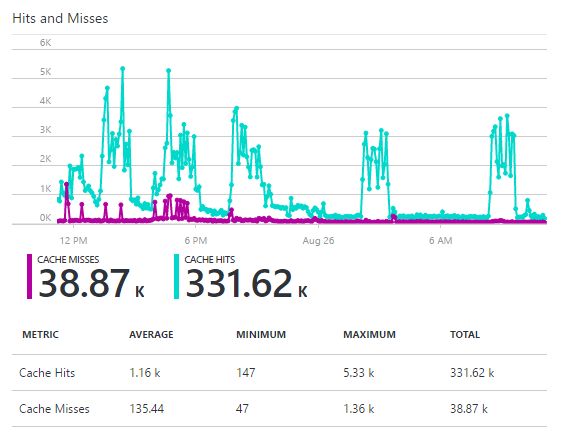
Screen 2. Dataflow stores in cache (blue) and blobs (magenta) for twenty-four hours.